Appliquer les travaux d’intelligence artificielle à l’industrie, tout le monde veut le faire. Mais l’immense majorité rencontre des obstacles sérieux dans cette démarche.
Tout acteur du domaine à connu cette frustration d’observer des résultats impressionnants issus du monde scientifique, mais qui se retrouvent très dégradés dès lors qu’on veut les appliquer à un problème « réel ».
De nombreuses raisons existent, entre la jeunesse théorique du Deep Learning et les difficultés à identifier les axes de robustesse d’un modèle pour industrialisation.
Mais s’il existe bien une constante dans ces obstacles, c’est le manque de donnée qui tôt ou tard met un coup d’arrêt aux projets. Nous travaillons depuis longtemps sur ces limites d’application et pouvons aujourd’hui proposer une méthodologie saine, efficace et permettant d’itérer sur une solution Deep Learning tant pour les entraînements que pour les tests de modèle.
Dans cet article, nous vous présenterons les approches basées sur la donnée synthétique, et au-delà sur une méthodologie qui permette de travailler sereinement.
Il n’y a jamais assez de données
Tout amateur s’étant déjà intéressé au sujet, est au courant de cette problématique : en IA, nous avons besoin d’une quantité démesurée de donnée. Le «toujours plus » est un axiome qui peut vite épuiser.
Dans le monde académique, les très grands acteurs comme Google et son JFT Dataset ont accumulé des dizaines de millions d’images différentes pour entraîner leurs réseaux.
Or, détenir une telle quantité de donnée est très souvent hors de portée pour un acteur industriel.
Rappelons également qu’une donnée, pour être utilisable, doit être annotée par un acteur humain. Quand bien même nous pouvons accélérer fortement cette annotation, ces annotations doivent être contrôlées avec rigueur par des experts.
Ces dernières, en effet, car serviront autant à entraîner (créer) nos modèles Deep Learning qu’à qualifier leur qualité de prédiction.
Dans ce dernier cas, une donnée annotée trop vite conduira à un modèle qui a l’illusion d’un bon fonctionnement, jusqu’au jour fatidique de l’industrialisation qui verra s’écrouler ce modèle.
Attention cependant, le but n’étant pas simplement d’accumuler beaucoup de donnée. Encore faut-il que cette donnée soit suffisamment variée pour reproduire la distribution du problème que nous désirons adresser. La donnée doit donc reproduire suffisamment de cas de figure variés, avec un certain équilibre.
Or, quel que soit le sujet industriel, les cas où nous manquons de données sont ceux typiquement où leur acquisition est plus complexe ou coûteuse. Exemples : les cas rares, les cas liés au fonctionnement d’un processus industriel coûteux à interrompre, etc
La tâche semble alors vite impossible, et peut conduire à chercher d’autres moyens d’améliorer un modèle IA. Par exemple, en travaillant une nouvelle architecture Deep Learning (un nouveau backbone en détection, par exemple), ou en fouillant les hyper-paramètres (par exemple via une approche Bayes+HyperBand, ou en Tensor V Programs).
Ces axes d’amélioration sont réels, mais d’expérience, ils donnent en général des améliorations beaucoup moins intéressantes qu’une donnée plus riche et mieux contrôlée.
Une solution évidente : générer de la donnée
Une solution, apparue depuis quelques années dans le monde scientifique, et tentée avec plus ou moins de succès dans le monde industriel, est de générer de la donnée pour augmenter les datasets.
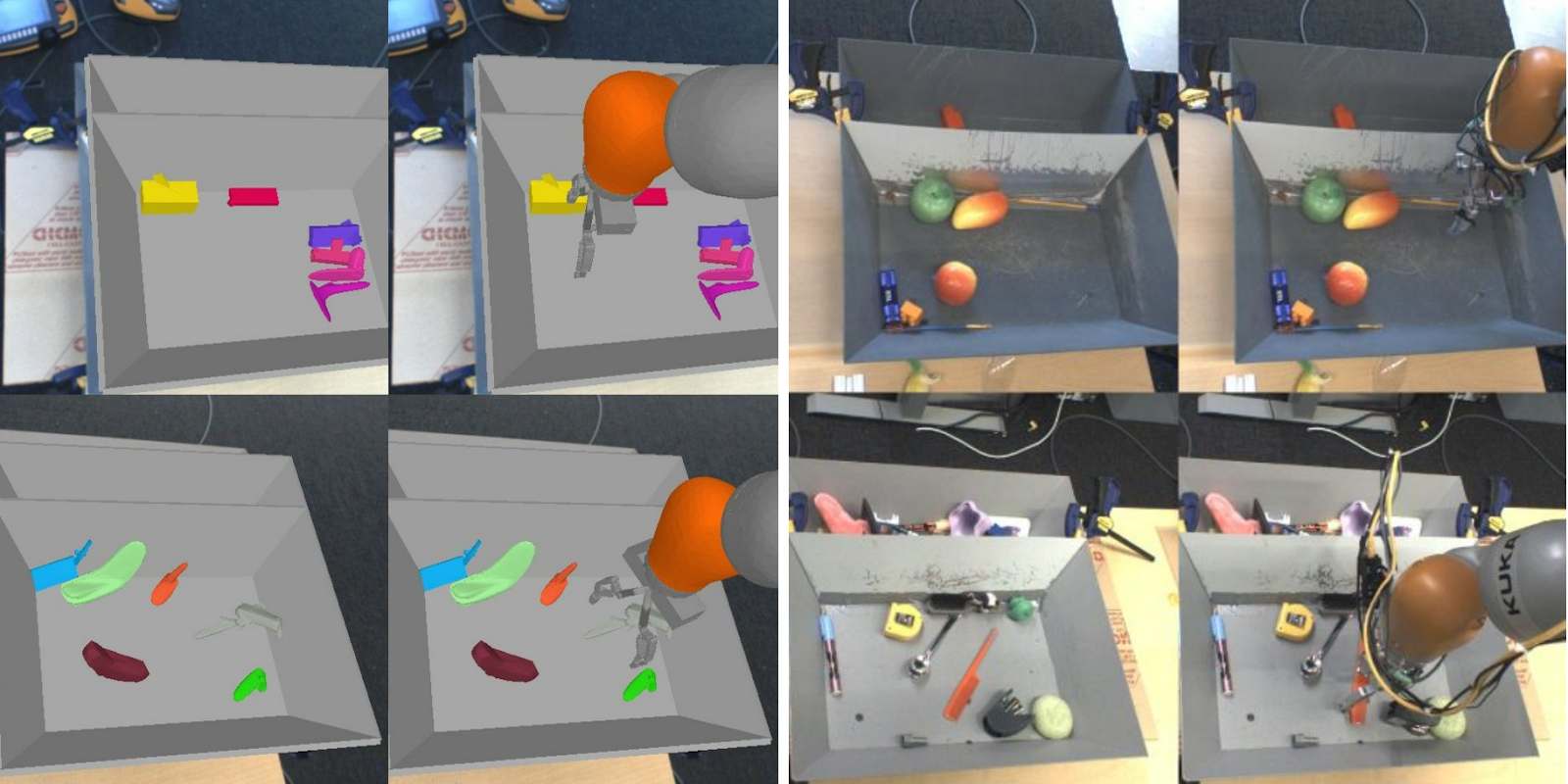
Cette approche est devenue un canon en recherche, notamment depuis les travaux d’OpenAI de « domain randomization » dans lesquels les chercheurs ont entraîné un agent robotique en environnement totalement simulé pour appliquer ensuite au monde réel ( Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World, Tobin et al, ). Plus récemment, OpenAI et Berkeley ont utilisé ces approches pour entraîner un quadripède à apprendre à se déplacer dans un environnement ouvert (Coupling Vision and Proprioception for Navigation of Legged Robots, Fu et al), cf schéma ci-dessous :
Si la robotique s’est saisie de cette approche, les problématiques de détection et localisation d’éléments, ou encore de détection d’anomalie, peuvent aussi bénéficier de ces méthodologies.
On pourrait même argumenter qu’on se rapproche du paradigme du Self Supervised Learning qui, lui, vise à entraîner un modèle sur une donnée plus générale pour apprendre des représentations bas niveau, pour ensuite le spécialiser sur un sujet.
Cette approche permettrait notamment de pouvoir tester plus largement un modèle : d’une part en visant dans la donnée générée des variances contrôlées et en observant les résultats du modèle ; et d’autre part en maximisant la quantité de donnée réelle utilisée en test, ce qui robustifie statistiquement les métriques de résultat.
Alors, suffit-il pour un problème industriel de générer de la donnée synthétique pour surmonter les problèmes ?
Hélas, et sans surprise, non.
Les approches naïves sont vouées à l’échec
Nous l’avons déjà observé. Une donnée, par exemple une image photo réaliste, est générée avec ses annotations. Un modèle IA est entraîné sur cette donnée de synthèse et semble fournir de bon scores.
Mais en application sur la donnée réelle, les résultats s’effondrent dramatiquement.
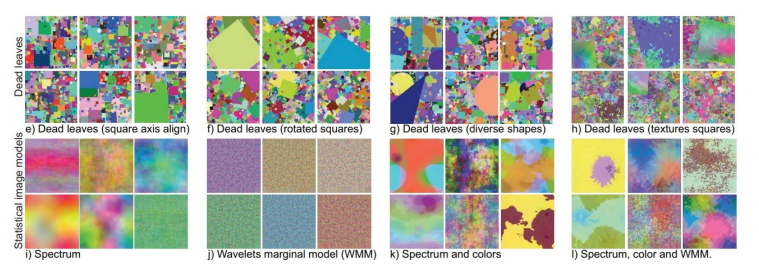
Nous retrouvons le démon du Distribution Drift spécifique au Deep Learning… Un élément déterminant dans la recherche de solution, vient d’un travail important réalisé en 2021 par Baradad et al : Learning to See by Looking at Noise.
Dans cette publication, les auteurs illustrent l’intuition issue du Representation Learning sur l’apprentissage de représentations hiérarchiques de l’information.
Ils illustrent le fait qu’il est possible de pré-entraîner un modèle sur des images très peu liées au problème cible (ici, des images de bruit, ou des générations hors sujets), pour peu que ces images d’entraînement puissent accompagner la création au sein du réseau de neurones de représentations fondamentales utiles.
L’idée fondatrice est la suivante : nous ne voulons pas une donnée synthétique qui simule le problème cible. Nous voulons une hiérarchie de données synthétiques dans laquelle on pourra noyer le problème cible, qui deviendra alors un cas particulier de notre génération. Via une méthodologie solide, nous pourrons itérer sur des améliorations concrètes du modèl
Une méthodologie indispensable
Comment mettre en œuvre un tel projet ? La méthodologie est, sans surprise, le nerf de la guerre si nous voulons garantir une amélioration correcte du modèle à nos clients.
1. Comprendre la distribution
Un dataset est fondamentalement un échantillonnage qui représente une distribution plus large, celle du problème que nous voulons adresser. Une distribution s’analyse, se mesure, se cartographie via la donnée disponible. Une analyse initiale de cette distribution, depuis la donnée, confrontée à une expertise métier du problème visé, est évidemment indispensable à toute action ultérieure.
2. Noyer la distribution
Partons d’un constat d’échec : nous ne pourrons pas créer une donnée totalement indissociable de la donnée manquante, inutile donc de brûler des mois sur une recherche de perfection vouée à l’échec. Car même si vous ne voyez pas de différence visuellement entre votre donnée synthétique et votre donnée réelle, un modèle Deep Learning pourra parfaitement utiliser des différences « invisibles » liées à un modèle de capteur, une forme de bruit lié à l’optique, etc. Mieux vaut donc chercher à noyer la distribution sur une approche hiérarchique correctement cadrée, dans la lignée des travaux de Baradad et al.
3. Contrôler la génération
Une génération qui ne peut pas être finement contrôlée, a un intérêt plus que limité. Tôt ou tard, nous voudrons générer des cas précis correspondant aux « trous » présents dans la donnée.
Hors, nous ne découvrirons ces cas particuliers qu’en testant le modèle contre de la donnée réelle ou synthétique et en identifiant les variances où le modèle est en défaut.
Laissons donc de côtés les Generative Adversarial Networks ou VQ-Variational Autoencoders, au moins au début, pour préférer un système déterministique parfaitement maîtrisé. Il sera toujours possible, dans un second temps, d’utiliser ces outils avec parcimonie, par exemple pour faire du transfert de domaine, ou sur de la génération conditionnée à l’image des récents modèles de diffusion
4. Avoir une boussole
Probablement le plus important. Personne ne veut attendre pendant des mois une donnée synthétique pour ensuite observer qu’elle ne fait absolument pas progresser le modèle. Nous cherchons avec nos clients à déterminer une « boussole », autrement dit, un modèle simple à entraîner lié à la donnée cible sur lequel on peut observer une amélioration. Cela permet d’agir par itérations et de vérifier la bonne direction des travaux de synthèse.
5. Adapter les entraînements
La donnée synthétique a un double but : pré-entraîner un modèle, et compléter l’apprentissage sur des cas particuliers. L’entraînement du modèle doit donc être pondéré entre les différentes données selon l’architecture de réseau de neurones et l’objectif visé, afin d’optimiser la qualité finale du modèle.
Aujourd’hui, trop de projets sont bloqués par le manque de données. Quand bien même un dataset suffisant aurait été accumulé pour entraîner un premier modèle, dès lors que l’on veut itérer pour améliorer cet outil, nous avons besoin d’identifier des variances manquantes et de les adresser. Un outil de génération synthétique permet ainsi d’améliorer incrémentalement un modèle en améliorant la donnée d’entraînement, comme il permet de tester correctement un modèle IA en questionnant chaque variance de la donnée d’une manière isolée.
Autrement dit, la donnée synthétique est aujourd’hui un excellent moyen d’aller au-delà du POC et d’industrialiser sereinement ces nouveaux outils.
Article écrit par Eric Debeir



Commentaires récents