Implementing artificial intelligence in industrial settings is a widespread aspiration. However, the journey is riddled with formidable challenges.
Practitioners often encounter the disheartening reality of witnessing promising outcomes in academic research, only to confront significant degradation when attempting real-world application.
Numerous factors contribute to this discrepancy, ranging from the relative infancy of Deep Learning theory to the complexities of identifying robust model axes suitable for industrial deployment.
Yet, amidst these challenges, a consistent bottleneck emerges: the scarcity of quality data, which invariably halts progress. Overcoming these limitations demands a refined methodology that facilitates iterative refinement of Deep Learning solutions for both training and model evaluation.
In this article, we unveil strategies rooted in synthetic data and introduce a robust methodology designed to foster a tranquil working environment amidst these complexities
Never enough data
Any enthusiast who has ever taken an interest in the subject will be aware of this problem: in AI, we need an inordinate amount of data. Always more” is an axiom that can quickly become exhausting.
In the academic world, major players such as Google and its JFT Dataset have accumulated dozens of millions of different images to train their networks.
However, holding such a large quantity of data is very often out of reach for an industrial player.
It should also be remembered that, to be usable, data must be annotated by a human actor. Even if we can greatly accelerate this annotation, it must be rigorously controlled by experts.
This is because the annotations will serve as much to train (create) our Deep Learning models as to qualify their predictive quality.
In the latter case, data annotated too quickly will lead to a model that has the illusion of working well, until the fateful day of industrialization when the model collapses.
Be careful, however, as the aim is not simply to accumulate lots of data. The data must be sufficiently varied to reproduce the distribution of the problem we wish to address. The data must therefore reproduce a sufficient variety of cases, with a certain balance.
However, whatever the industrial subject, the cases where we lack data are typically those where its acquisition is more complex or costly. Examples: rare cases, cases linked to the operation of an industrial process that’s costly to interrupt, etc.
The task then quickly seems impossible, and may lead us to look for other ways of improving an AI model. For example, by working on a new Deep Learning architecture (a new detection backbone, for example), or by delving into hyper-parameters (via a Bayes+HyperBand approach, for example, or in Tensor V Programs).
These areas for improvement are real, but in our experience, they generally produce much less interesting improvements than richer, better-controlled data.
One obvious solution : generate data
One solution, which has emerged in recent years in the scientific world, and has been tried with varying degrees of success in the industrial world, is to generate data to increase datasets.
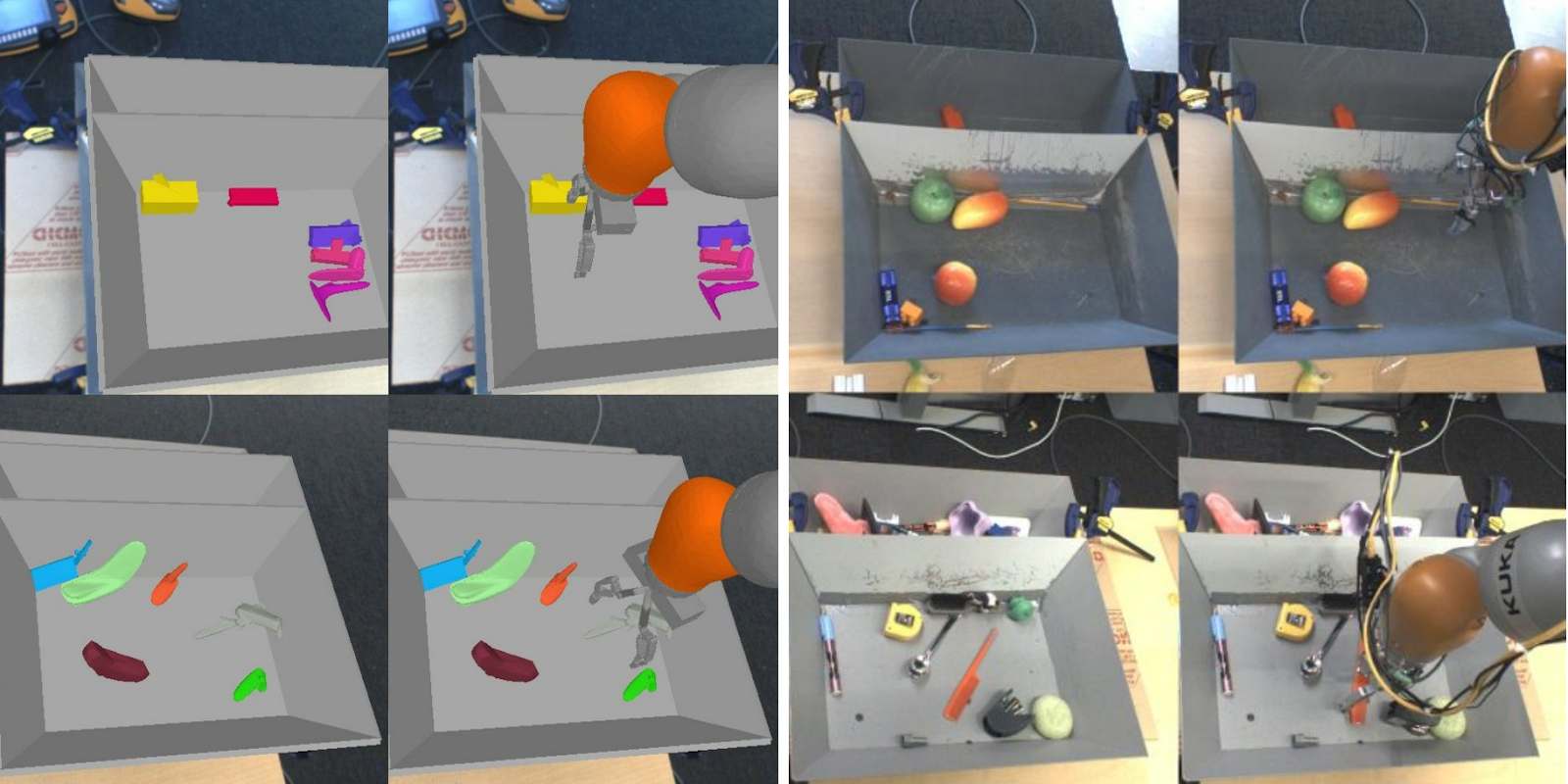
This approach has become a research canon, particularly since OpenAI’s work on “domain randomization”, in which researchers trained a robotic agent in a fully simulated environment and then applied it to the real world ( Domain Randomization for Transferring Deep Neural Networks from Simulation to the Real World, Tobin et al, ). More recently, OpenAI and Berkeley have used these approaches to train a quadcopter to learn to move in an open environment (Coupling Vision and Proprioception for Navigation of Legged Robots, Fu et al), see diagram below :
Robotics has seized on this approach, but problems such as feature detection and localization, or anomaly detection, can also benefit from these methodologies.
It could even be argued that we’re getting closer to the Self Supervised Learning paradigm, which aims to train a model on more general data to learn low-level representations, and then specialize it on a particular subject.
In particular, this approach would make it possible to test a model more extensively: on the one hand, by targeting controlled variances in the generated data and observing the model’s results; and on the other, by maximizing the amount of real data used in testing, which statistically robustifies the result metrics.
So, is it enough for an industrial problem to generate synthetic data to overcome the problems?
Sadly, and unsurprisingly, no.
Naive approaches are bound to fail
We’ve already seen this. A piece of data, such as a photo-realistic image, is generated with its annotations. An AI model is trained on this synthetic data and seems to deliver good scores.
But when applied to real data, the results collapse dramatically.
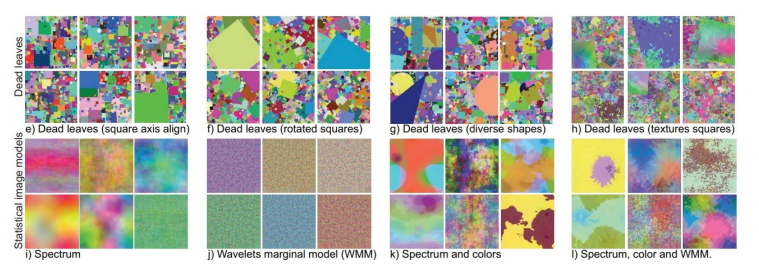
We are back to the Distribution Drift demon specific to Deep Learning… A decisive element in the search for a solution comes from an important work carried out in 2021 by Baradad et al : Learning to See by Looking at Noise.
In this publication, the authors illustrate the Representation Learning intuition on learning hierarchical representations of information.
They illustrate that it is possible to pre-train a model on images that have very little to do with the target problem (in this case, noise images, or out-of-topic generations), provided that these training images can accompany the creation within the neural network of useful fundamental representations.
The basic idea is this: we don’t want a synthetic data set that simulates the target problem. We want a hierarchy of synthetic data in which we can embed the target problem, which will then become a special case of our generation. With a solid methodology in place, we’ll be able to iterate on concrete improvements to the model.
An indispensable methodology
How do you implement such a project? Methodology is, unsurprisingly, the sinews of war if we are to guarantee our customers a correct improvement of the model.
1. Understanding distribution
A dataset is basically a sampling that represents a wider distribution, that of the problem we want to address. A distribution can be analyzed, measured and mapped using available data. An initial analysis of this distribution, based on the data, combined with business expertise in the targeted problem, is obviously essential to any subsequent action.
2. Drowning out distribution
Let’s face it: we won’t be able to create data that’s totally indistinguishable from the missing data, so there’s no point wasting months on a quest for perfection that’s doomed to failure. Because even if you can’t see any difference visually between your synthetic data and your real data, a Deep Learning model will be perfectly capable of using “invisible” differences linked to a sensor model, a form of noise linked to optics, and so on. So it’s best to try to nest the distribution in a properly framed hierarchical approach, along the lines of Baradad et al.
3. Controlling generation
Generation that can’t be finely controlled is of limited interest. Sooner or later, we’ll want to generate specific cases corresponding to “holes” in the data.
But we can only discover these special cases by testing the model against real or synthetic data and identifying the variances where the model is at fault.
So let’s leave aside Generative Adversarial Networks or VQ-Variational Autoencoders, at least initially, in favor of a perfectly mastered deterministic system. It will always be possible, at a later stage, to use these tools sparingly, for example for domain transfer, or for conditioned generation, as in the case of recent diffusion models.
4. Having a compass
Probably the most important. No-one wants to wait months for synthetic data, only to find that it does absolutely nothing to improve the model. We work with our customers to determine a “compass”, in other words, a model that is easy to train and linked to the target data, on which an improvement can be observed. This makes it possible to iterate and check that the synthesis work is going in the right direction.
5. Adapting workouts
Synthetic data has a dual purpose: to pre-train a model, and to complete training on specific cases. Model training must therefore be weighted according to the neural network architecture and objective, in order to optimize final model quality.
Today, too many projects are blocked by lack of data. Even if a sufficient dataset has been accumulated to train a first model, when we want to iterate to improve this tool, we need to identify missing variances and address them. A synthetic generation tool thus enables us to incrementally improve a model by improving the training data, just as it enables us to correctly test an AI model by questioning each variance in the data in isolation.
In other words, synthetic data is an excellent way of moving beyond POC and industrializing these new tools.
Article écrit par Eric Debeir



Recent Comments