
Artificial intelligence has always been characterised by its ability to suddenly break down technical walls that were thought to be unmovable. Here is an update on the new developments enabled by AI.
Article written by Eric Debeir, lead data scientist
Diffusion models?
You have probably heard about one of these recent revolutions, with the generation of stunning images from descriptive sentences. If you haven’t, here’s a quick update: for a few months now, it has been possible to create new images based on neural networks using a number of tools… A few examples:



- Prompt: A full shot of a cute magical monster cryptid wearing a dress made of opals and tentacles. chibi. subsurface scattering. translucent skin. caustics. prismatic light. defined facial features, symmetrical facial features. opalescent surface. soft lighting. beautiful lighting. by giger and ruan jia and artgerm and wlop and william-adolphe bouguereau and loish and lisa frank. sailor moon. trending on artstation, featured on pixiv, award winning, sharp, details, intricate details, realistic, hyper-detailed, hd, hdr, 4k, 8k.
- The war by Robert Capa. Prompt : Complex 3 d render of a beautiful porcelain cyberpunk robot ai face, beautiful eyes. red gold and black, fractal veins. dragon cyborg, 1 5 0 mm, beautiful natural soft light, rim light, gold fractal details, fine lace, mandelbot fractal, anatomical, glass, facial muscles, elegant, ultra detailed, metallic armor, octane render, depth of field
- Prompt: Complex 3 d render of a beautiful porcelain cyberpunk robot ai face, beautiful eyes. red gold and black, fractal veins. dragon cyborg, 1 5 0 mm, beautiful natural soft light, rim light, gold fractal details, fine lace, mandelbot fractal, anatomical, glass, facial muscles, elegant, ultra detailed, metallic armor, octane render, depth of field
These examples were randomly selected from the excellent website : https://lexica.art/
Many research projects have tackled this subject of image generation: Imagen by Google , DALL.E . But it was a more recent work that revolutionised the Internet, particularly because the models were, this time, freely available under an open source licence: the Latent Diffusion Models. Since the release of this tool, a huge debate has emerged within the illustrator community:
- Can these models be seen as tools for artistic creation? Instinctively, no, and yet we are only scratching the surface of the possible uses of these models…
- What about the competition tomorrow between illustrators who will spend a certain amount of time on their work, and the exploitation of an AI model? It is indeed likely that in many cases, the clients will not necessarily be sensitive to the added value of a real artistic creation?
- As these models have been trained on a gigantic image base comprising mostly the work of real artists, how can the results of the model be considered, especially when the users do not hesitate to use the names of artists still in activity( https://huggingface.co/spaces/stabilityai/stable-diffusion/discussions/731 ou https://huggingface.co/spaces/stabilityai/stable-diffusion/discussions/688 ) ?
Emergence of diffusion models
Beyond these debates, from a technical point of view, we can see the emergence of a new family of artificial intelligence tools (the “diffusion models”).
This family of tools is already showing prodigious results on image learning.
We would like to study together, at a high level, the particularity of these tools, how they can be applied to other problems, and the general opportunities brought by these models. However, we must recognise that the scientific community of Deep Learning has largely taken hold of this subject with an explosion of research work.
For example, the research teams at NVIDIA (the undisputed leader in generative models) have recently proposed a publication which was recognised as an outstanding paper at the NEURIPS 2022 conference, in which they expand on these models and propose a better understanding of them.
Beyond images: audio, 3d, human movement…
Perhaps we should start there. If the application to images has been widely publicised on social networks, it would be very limited to stop there. We are indeed facing a new architecture that already applies to many other domains, and that tomorrow could be applied to particular problems on a business data.
The application to images first is easily explained, and is in fact a common phenomenon in Deep Learning. Indeed, the data is much simpler to retrieve, many applications exist, and we are very tolerant of marginal errors in a generated image, much more so than we would be with generated music.
That said, we have already seen some very different and exciting applications.
New applications
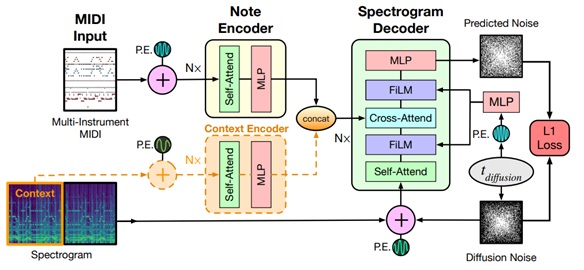
“Multi-instrument Music Synthesis with Spectrogram Diffusion” is an example of an application to music, where the diffusion model will generate music excerpts with multiple instruments, working directly on the spectrograms. A conditioning mechanism will allow a piece of music to be continued over time. This work is not yet auditorily impressive, and we are therefore not at the level of image generation where a simple amateur could easily believe that the work was generated by a human.
Nevertheless, it is clear that things are moving fast. The latest interesting music generation work was by OpenAI with their Jukebox which was already very promising. The most recent publication is the work of the Magenta de Google which specialises in Deep Learning adapted to music, with many exciting works.
In the future, this type of work can be applied to any approach to the audio domain. Indeed (we will discuss this later), such a model does not just generate data, but approximates its variances and controls them.
Modelling and generation of human movements
Another exciting approach, “Human Motion Diffusion Models”
It aims to model and generate human movements, particularly for animation purposes. This work aims to be able to easily generate the movement of a 3d model representing an individual, via a simple sentence describing the action to be performed. This work is important because by learning to generate a human movement, it implicitly learns to “summarise” or “compress” these movements, and can therefore make it possible to use detected movements to normalise or qualify them.

Generation of three-dimensional volumes
The last example is the generation of three-dimensional volumes directly from a generation sentence. Several works already exist, we recommend the work of Google Research and Berkeley “DreamFusion: Text-to-3D using 2D Diffusion”.
The generation of three-dimensional volumes is often an obligatory step in modelling, and this type of tool can make it possible to feed new volumes into a processing architecture very quickly with a very simple to use generation axis. Beyond that, similar to the image generation model, such a model learns the correspondence between certain terms and their expression in three dimensions, whether we are talking about the subject, the style, the position, etc. Future work will (hopefully) allow for better control of this type of generation via a more relevant separation of the generation.
And the list is growing every day. We have recently seen proposals for scientific approaches to localized detection using diffusion models, or even enriching BERT-type language models with this method…
Generative models: for which uses?
A brief reminder
Generative models are a family of models in Deep Learning (AI) specialising in data generation. Trained on a dataset composed of many elements, these models learn to generate a data that is not directly present in the dataset, but that corresponds to the distribution of the data as represented by that dataset. In other words, the objective of such a model is to learn the global rules specific to all the elements of the dataset in order to succeed in generating data that could have been present in this dataset. Mathematically, this is called learning a distribution. Obviously, such a model is very dependent on the variance of the data present in the dataset.
These models were science fiction until 2013/2014 with the appearance of two major families of generative models.
First family of generative models
The first family is Kingma’s Variational Autoencoders (VAE). At a very high level, these models learn to simplify a datum as much as possible while learning the diversity (mathematically, the distribution) of this datum. They are therefore very valuable tools for approximating the complexity of a data item, with the possibility of applying numerous cross-cutting approaches: anomaly detection, clustering, etc. These tools therefore go beyond the simple generative model, and have made it possible to create AI systems with a notion of uncertainty in the predictions.
Second family of generative models
The second family, which is a little better known, is Goodfellow’s Generative Adversarial Networks (GAN). This approach is confusing at first, with a “duel” between a model learning to generate data and another model learning to criticise the generation. Nevertheless, it allows for the easy creation of good quality generative models. The famous site “This person does not exist” presents portraits of individuals that do not exist, but have been generated by Nvidia’s StyleGan.
The consensus until recently was that GANs could give better results in terms of visual quality, but that VAEs were much better at learning the diversity of a dataset and were therefore a more powerful tool for working on complex data. Obviously, in Deep Learning, things never stay stable for very long. VQ-VAEs have become established in the last three years, and then diffusion models came along.
Interest in business and/or industrial processes
The interest of these tools in business and/or industrial processes should not be underestimated.
A generative model is a valuable tool for all data analysis operations. It could even be argued that their ability to generate data is not their main attraction from an applied point of view, compared to the possibility of exploiting them as tools for data exploration and analysis.
Approximating the distribution of a data item means becoming able to identify the major variances of that data item, alone or in combination, and then being able to question any new element in the face of that distribution.
Anomaly detection, data simplification, taking into account uncertainty in a prediction or annotation or clustering are only the tip of the iceberg. Beyond that, all these models learn to project the data into a much nicer space, in which simple arithmetic operations give rise to significant modifications of the data. To perhaps make this approach clearer, let’s take the example of images, and NVIDIA’s StyleGan generating faces. It becomes possible to edit images very finely, not by manipulating the pixels of the image, but by working on the projection of the data made by the model:
(from https://github.com/yuval-alaluf/hyperstyle)
Scattering models are therefore more than a stroke of brilliance reserved for image generation. As generative models, they have many applications, the majority of which have probably not yet been discovered.

Diffusion models, which opportunities?
What are the future interests?
The distribution models are therefore only just emerging, but we can already think about what these new tools will bring us in terms of use, beyond simple image processing. For this slightly acrobatic exercise, three sources can fuel our reflection:
1/ The exploitation of approaches resulting from variational inference (VAE or Normalizing Flows), which have pushed these models beyond the simple generation of data, and which are now used as tools
2/ Observation of what the community produces on the Internet from the recent diffusion of the Stable Diffusion model, where new uses appear regularly.
3/ We see that this approach is already applied to other types of data (audio, human movement, 3D volumes), and can therefore imagine what these new data will bring
Details of the points raised
The first point is probably the most fundamental, but the most complex to predict. A diffusion model learns to approximate a data in its distribution (in the mathematical sense). This implies that it can be used for problems such as anomaly detection (such as predictive maintenance). The next few months will show whether the academic world can produce results on this subject. Obviously, we must keep a precautionary principle, and not use a tool just because it is recent and ‘sexy’. Rather, we should question to what extent this new tool could improve our ability to address certain problems. Anomaly detection is a sea serpent in the field of Machine Learning: it encompasses a large number of very different subjects with very variable complexities. A diffusion model offers an original approach, as it allows to iterate on different versions of the data, by re-projecting it into the “normal” space that has been learned (via noise or denoising iterations). It is likely that some problems can be addressed in this way in a new way. Note that one interest here could be to locate the anomaly in the image in a more efficient way, and to expose a distance between this anomaly and a “norm” learned by the model.
The second point is less scientific, but should not be ignored. There is as much potential for innovation in a fundamental discovery as in the exploration of new uses. A simple follow-up of the experiments carried out with Stable Diffusion shows new approaches every week. For example, while everyone knows that you can generate an image from text, few know that it is also possible to generate an image by defining the elements that should appear in a global way, via location rectangles (diagram from Rombach et al):
Or even, via a “sketch” in coloured flat tints:


Last example in “inpainting”, where we delete a part of the image and ask the diffusion model to regenerate the missing part. This will be done while respecting the rest of the image still visible, producing a “credible” image by generating the missing part:

We are therefore faced with a very polymorphic tool. Moreover, the conditioning mechanism (allowing to learn a link between input and generated image) is relatively free and only asks to be adapted to new concepts.
We are therefore faced with tools that go beyond simple generation, to perform domain conversion, with many applications. Given a specific type of data that models a business or industrial problem, we can map that data and modify it in an amazing way by conditioning it to simpler information.
Concluding on the last point, we can observe that the broadcasting models arrive on many different types of data (audio, image, text, etc.) We can therefore already observe that many types of more or less complex signals will be able to know the same type of application.
However, the majority of industrial systems offer monitoring based on numerous probes, cameras and microphones, whose excessive complexity is a hindrance to advanced analyses.
Deep Learning offers tools to reduce this complexity by minimising the loss of information (the high-level features in a trained model). Diffusion models offer us an innovative approach of this type. For example, to qualify the noise present in a signal, and to decide if this noise is external to the system under study or if, on the contrary, this noise is a new component reflecting an important problem, diffusion models could be a very relevant tool insofar as they learn precisely how to noise or denoise the data…
Beyond that, let us recall that these approaches also allow the creation of correspondences between different types of information. OpenAI created DALL-E by bringing together learning on text and learning on images. We can therefore hope to have tools that allow us to convert one piece of information into another, for example, by transforming a temporal signal of good mechanical functioning into a text explaining this good functioning. At this stage, it is high time to experiment and look forward to the next scientific work.
Obviously, at Kickmaker we are closely monitoring these subjects and are already experimenting in order to be able to offer you the best possible solutions tomorrow, combining the innovative quality of this work with our rigorous engineering implementation. Indeed, beyond the scientific revolution, our challenge is to transform these experiments into usable and controllable tools. Follow us, and if you want to go a little further, let’s talk! 2023 will be an exceptional year in following these application opportunities.
Article written by Eric Debeir, lead data scientist
 Vivatech day 2: the momentum continues
Vivatech day 2: the momentum continues


Recent Comments